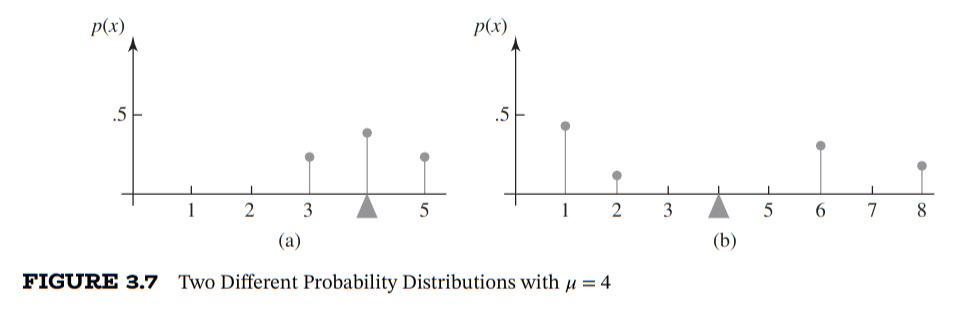
Sometimes even though the Expected Value of some distribution equals, they are more/less variant:
Although both distributions in the figure above have the same expected value, they clearly are different distributions, where the second is more varied than the first. We have a quantitative way to describe this variance:
Variance, standard deviation
Let have pmf and expected value . Then the variance of , denoted by or or is:
The standard deviation of denoted or or is just:
Where does this come from
The idea is that is the average distance from . Think of the function as doing the norm, so then square rooting will find the distance from .
See [[handout05-DiscreteRVs-350F24_annotated.pdf#page=4]] for some examples of computing these.
Chebyshev's Inequality
Let be a discrete rv with Expected Value and standard deviation . Then for any :
That is, the probability is at least standard deviations away from the mean is at most .
Proof
Let denote the event . Begin by rewriting out the definition of :
Solving and simplifying gives the desired result. The middle step uses the variance shortcut.
☐
Variance Shortcut
Proof
See [[handout05-DiscreteRVs-350F24_annotated.pdf#page=5]].
☐
If is a linear function, then we get the following: