Lecture Note Review (Finals OS)
Systems Review
- A
pipeis twofds connected by a buffer. fork-edfd's are copied to the child. Doing apipethen aforkgives syncronizedfd's`dup2is helpful for duplicating afdinto something that already exists, likestdin.
malloc
Recall our memory format is (from top high address to low low address):
- Stack: holds callback info
- Region between the data and stack segments
- Data segment (for constants, heap variables)
- Text segment (for
PCinstructions for this program)
In this assigment we:
- Used
sbrkto increase the heap's (data segments) top address
C Compilation and Linking
*.a: archive libraries. Linked at link time w/ the object files.*.so: dynamic libraries. Linked at load time w/ the.outfrom the linker.
History of UNIX
- The I,J,K in Dijkstra's Algorithm are in order. That's how you spell it.
- The idea of multiprogramming: the idea of having multiple programs in memory so that if one is fail/done, then you can keep running the CPU.
- Time sharing: you switch programs when your stuck or when a certain amount of time has passed
Processes and Privilege
Most processes spend most of their time in the blocked state.
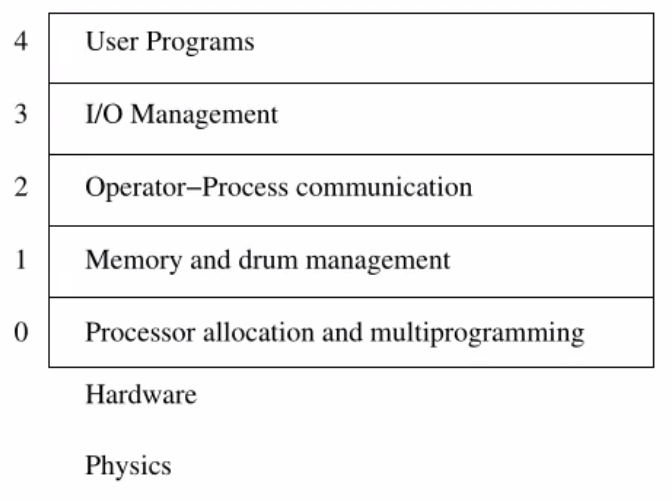
There's a distinct difference between mechanism and a policy:
- Ex: A PHD program has limits on 7 years of staying.
- The mechanism is giving the degree or kicking people out.
Most grad schools cut off funding as your years go on, to incentivize you to get out at the wallet.
Context Switching (Threads)
You essentially are doing the following calling conention:
- Before the call:
main()puts parameters at a known location. - Call a function: Push
raand jump tofooaddress. - Before body: Set up our stack frame
- Before return: Clean up and
leave:
leavedoes amovq %rbp, %rspand thenpopq %rbpretdoespopq %rip
- After return: Clean up
- Our clean up would just be to move our stack pointer however much space back down.
We can use different schedulers like round robin to have different behaviors.
Race Conditions/Critical Sections and Solutions
For each of these solutions, think about if we had an interrupt right before setting whatever lock=true;, and seeing if two threads call that while the lock is already true from the first assignment.
Sol'n #1: Busy Waiting
// A
for(;;)
{
while(turn == 1)
{
/* spin */
}
// critical
turn = 1;
// noncritical
}
// B
for(;;)
{
while(turn == 0)
{
/* spin */
}
// critical
turn = 0;
// noncritical
}
This alternation strategy works, but it's still busy-waiting. Notice that it works because you give away control, rather than seize it per thread.
Sol'n #2: Peterson's Solution
int turn;
bool interested[2];
void enter(int self)
{
int other;
other = 1 - self; // if self is 0 then other is 1, and vice versa
interested[self] = true;
turn = self;
while((term == self) && interested[other]); // wait for turn
// enter the process (all others block)
}
void exit_region(int self)
{
interested[self] = false;
}
Think about an example of going through, especially if both set turn at the same time.
- Both try to set
turnand thus their owninterest turnis one of the written values- The thread that got it's value in
turnbreaks from thewhileand thus runs - The other thread has to wait in the
whileand thus blocks.
Sol'n #3: Hardware Lock Variables
The problem with these is that:
- They require extra hardware
- You are likely forced to busy wait anyways, so there's no performance benefit
Sol'n #4: Non-Busy Waiting
Use semaphores:
We need these to be atomic operations! For the producer consumer problem:
Scheduling
Criteria:
-
fairness: make sure each process can get its fair share
-
efficiency/utilization: keep the CPU busy as close to 100% of the time (don't have busy waits)
-
response time: minimize response time for interactive users
-
turnaround: minimize turnaround time for batch users.
-
throughput: maximize the number of jobs processed per time
Examples (non-preemptive, non-interrupting):
- FCFS (first come first served): provably optimal. Probs: Starvation
- Round Robin: everyone gets a
quantaof time for their turn. - Priority Scheduling: Give each job a priority and choose the most important one. Break into classes
- IO Bound (they go first, block)
- Compute bound after (they don't block)
- Ex: CTSS: Compatible Time Sharing System
- Processes that use the whole quantum (usually compute bound) move down the rank, and if they don't they go up.
Deadlock
To have deadlock, you must have all:
- Mutual-Exclusion
- Holds and Waits
- No-preemption
- You must have circular wait (like shown in the figure)
Did someone say deadlock? OMG hit game from Valve Software set in the TF2 Universe?!?!?!!
Sol'n #1: Dijkstra's (Bankers) Algorithm
Model Resources like a line of credit.
Process declare max need in advance.
Test states for safety.
See Lecture 13 - Disk Drives#Multi-Dimensional Banker's Alg. for an example of its use.
IO Software
- Write something to the control register (see the docs for what specifically to write. It's device dependent)
- Wait a while (keep checking the status register to see if it's done)
- Check status register (again)
- Respond appropriately
It's best to have interrupts help notify the process when the IO is done. These are handled by the written ISR's so that when an interrupt does happen, you know what will be ran.
Memory Management
- Monoprogramming: only allow one program in memory. It's simple, and honestly a lot of cheap options would use this.
- Multi-programming/Fixed Partitions: we take our machine, divide it into chunks (of varying size) and load a program into each chunk.
- Relative Addressing: All of a programs addresses are relative to the base address give to the program.
- It'd be hard to have a Linked List to hold all the relative addresses, and then on a new program run have to calculate the relative addresses for every address.
- Base Register: For every memory reference, add a base register for that programs base offset.
The problem, similar with malloc, experiences fragmentation. What can we do about it? We can, similar to malloc, try to keep track of allocated memory via:
- bitmap: one bit per allocation unit of memory to track allocated (set) or not.
- Keep a LL (list) of what's allocated and not allocated.
Virtual Memory
It's essentially caching real-address references, where we are *always* converting from VA to RA (virtual address to real address)- pages: virtual memory is divided by these
- frames: real memory divided into these
- Loaded pages are in a frame
- Unloaded pages are in a backing store (ie: a drive)
- Not Recently Used (NRU)
- Prefer any unmodified page, since we don't have to go to storage to let it know that it's been modified.
- Divide into 4 categories, based on reference bit
and modified bit :
| 0 | 2 | |
| 1 | 3 | |
| Essentially, being not read takes more precedence than being not modified, so it's: |
- Oldest Page Evicted: remove the oldest page from a FIFO (when it entered ever).
- Combine the above two, use a FIFO for old pages and if it's
read then send it back to the end. This is the:
Due to the nature of the clockwork structure of the FIFO, (5) above is called the Clock Algorithm.
- Least Recently Used (LRU): on reference
reset the position in the queue. - Not Frequently Used: Use a
counterstarting at 0 for every page. Every so often add thebit and clear it. On a PAGE_FAULTevict the lowestcountpage. You can alternatively shift to the left so that pages don't starve other pages (over time you'll shift enough to reset back to 0).
Paging Policies
When:
- You can do demand paging: fetching a page when it's referenced.
- Pros: Simple, no waste.
- Cons: It's demanding! Imagine getting a
PAGE_FAULTevery single memory reference! This means rough starts, and no opportunity to share costs.
- Pre-paging: Try to load everything at once (at the beginning).
- Pros: It fixes the many
PAGE_FAULTs we get from the previous approach. You can now share costs. - Cons: You will quickly run out of memory (you will do this for every program, so there's a lot of wasted memory spaces that are not used). And more importantly, how could you know?!?!? You would need to know the addresses at runtime, which may be impossible for dynamic programs.
- Pros: It fixes the many
- Swapping: If paging pressure (from pre-paging) is too much, have a process sit out.
You'll also need a medium PAGE_SIZE because:
- if your page size is too big, then only a few processes are happy about it (fragmentation)
- if your page size is too small, the time spent for page management is too large, and you lose some of the spatial locality properties
Usually common sizes are 4K or even 64K (especially with larger memory sizes now).
File Allocation Table
Using file zone numbers, you have a table of zones that dictate where files (or parts of files are):
Filesystem Performance
In general, you want to cache file-references because if they are referenced again in time (temporal locality) then you are ready. Using buffer caching, we can hold recently used blocks in case we reuse them. With this:
- you need to periodically flush the cache
- you can use the same replacement algorithms that we used for pages in memory (ie: please use LRU). Disks are so slow compared to memory that it's worth it to do.
- ... but what's that gonna do? You'll get a lot of locking of constantly used pages, hence why we flush the cache.
Filesystem Reliability
To check them for consistency:
- Create an array of counters for allocated and free blocks:

- Sweep through the filesystem and free list and increment the aprpopriate counter each time a block is found.
If all goes well each block will be found in one of the lists:

If not there's a problem:

You may have the following problems:
- Missing block: the solution is to place it in the
freelist - Allocated block in
freelist: remove it from thefreelist - Block allocated twice: copy the block to a
freeone and hope things work out ok
- Do the same thing for references counts from directories to
inodes.