Lab 5 Exercises - Brian Mere
1
Proof
The CPU is idle only when all of the processes are idle (because on a context switch it couldn't switch to a utilizable process). The chance of this happening is only when all 4 processes are in a idle state for IO, with probability:
☐
2

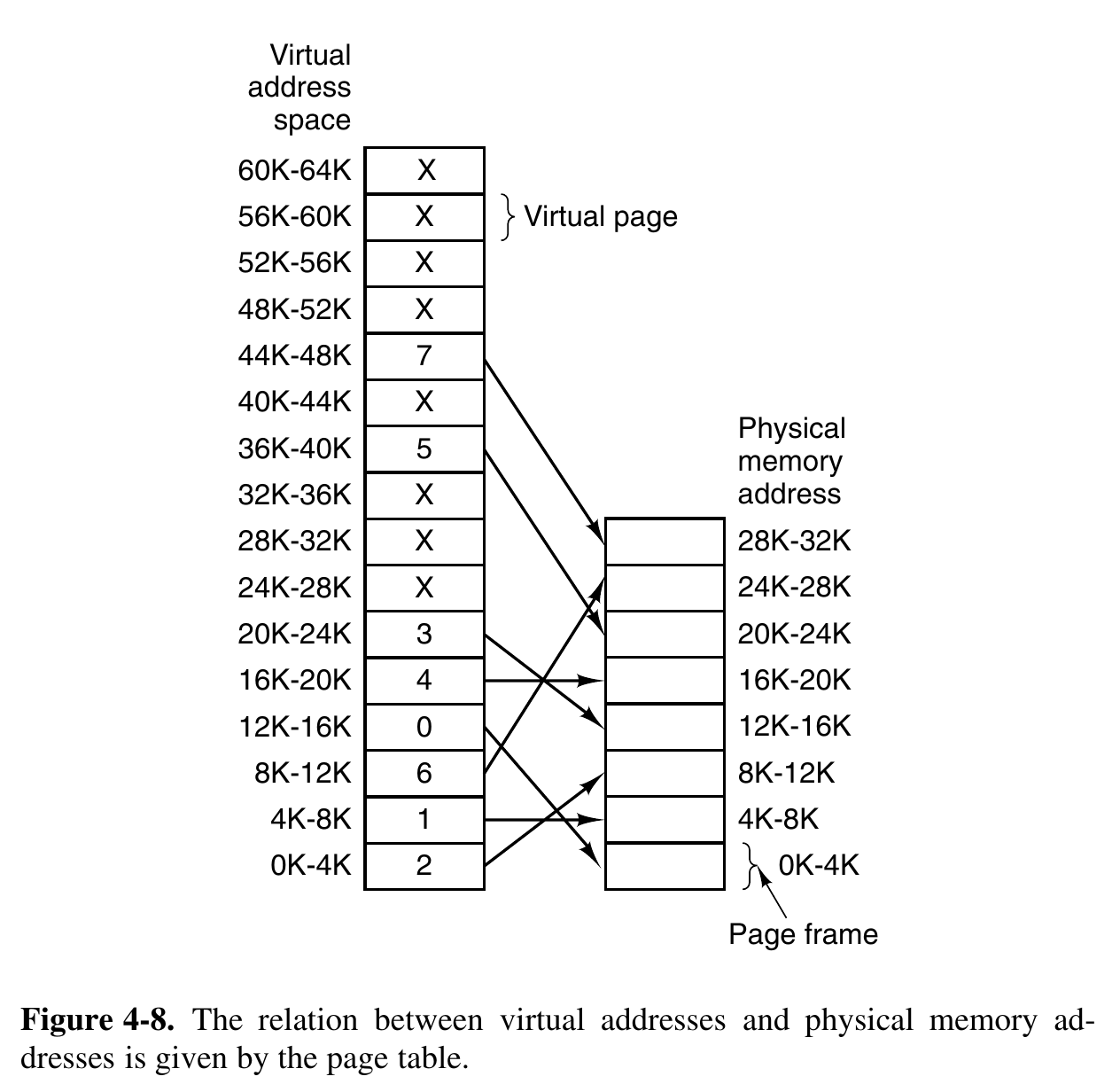
Proof
a. 20 is physical memory 0K->8K + 20 = 8 * 1024 + 20 =
b. 4100 is physical memory 4K->4K + 4 =
c. 8300 is physical memory 8K->24K + 108 =
☐
3

Proof
Since there's 9 + 11 = 20 bits used for the page table entries, then the offset dictates the bit size of the page. Thus it is
☐
4

Proof
a. Page 0. NRU looks at the class determined by
| 0 | 2 | |
| 1 | 3 | |
| We use the lowest class first, so we need a page with |
b. Page 2 since it has the lowest timestamp (and thus is the oldest loaded).
c. Page 1 since it has the largest loaded timestamp (and is the least recently used).
d. Page 0 since it hasn't been read, so even though page 1 would be looked at first it would get it's
☐
5

Proof
0: 0713 (oldest is to the left, 4 page faults)
1: 7132 (fault)
2: 7132 (no fault)
3: 7132 (no fault)
4: 1320 (fault)
5: 1320 (no fault)
6: 1320 (no fault)
So 6 page faults, with final pages loaded as 1320.
☐
6
Repeat 5 with LRU replacement
Proof
0: 0713 (NRU is to the left, LRU to the right, 4 page faults)
1: 7312 (fault)
2: 1327 (no fault)
3: 1372 (no fault)
4: 3720 (fault)
5: 7201 (fault)
6: 2013 (fault)
So 8 page faults with final pages loaded 2013.
☐
7

Proof
If the memory is doubled, then there is half the amount of page faults (since the intervals are halved) so then we have:
☐
8

Proof
Users don't know the internal structure of directories, so they need a system call to handle it. All processes are virtualized, so there is no way anything other than the OS can know what are physical addresses, and thus there is know way for the user process to know where to start reading.
☐
9
Proof
You save time by not having to go far in address space to read the data after reading the inode. You get performance benefits via caching (you'll pull in some of the data for free after referencing the inode). The disk also doesn't have to move as far physically.
☐
10

Proof
The function for
The average divides this by
---
title:
xLabel:
yLabel:
bounds: [0,1, 0, 40]
disableZoom: false
grid: true
---
f(x) = x + 40(1-x)
☐
11

Proof
Case 1: Add rotation latency + seek time + transmit time
Case 2: Add rotation latency + seek time (cylinder seek + track seek) + transmit time
The above proposed solution is incorrect. The correct is as follows:
a. (unoptimized case) Average seek of 5ms:
Here it's:
b. (optimized case) Average seek of 100
thus:
Essentially, in trying this problem I failed to have the rotation latency be per block too. Adding in the actual rotational delay would be:
and:
respectively.
☐
12

Proof
Elinor is right (Carolyn is wrong). Even though the space is cheap and thus we have more of it, it does makes sense that you'd get a performance boost by writing to the table after every inode lookup (as then you don't have to search the table). However, for systems with many files (like most are), eventually your table will get so big that you'll be spending more time amending many duplicate inode entries in the table when you write to one file.
☐